| .github/workflows | ||
| src | ||
| test | ||
| .gitattributes | ||
| .gitignore | ||
| benchmark.js | ||
| CHANGELOG.md | ||
| eslint.config.js | ||
| hyparquet.jpg | ||
| hyperparam.png | ||
| LICENSE | ||
| package.json | ||
| README.md | ||
| tsconfig.build.json | ||
| tsconfig.json | ||
{kind=link}
{kind=link}
hyparquet



![]()
![]()
Dependency free since 2023!
What is hyparquet?
Hyparquet is a JavaScript library for parsing Apache Parquet files in the browser. Apache Parquet is a popular columnar storage format that is widely used in data engineering, data science, and machine learning applications for storing large datasets. Hyparquet is designed to read parquet files efficiently over http, so that parquet files in cloud storage can be queried directly from the browser without needing a server.
- Works in browsers and node.js
- Pure JavaScript, no dependencies
- Supports all parquet types, encodings, and compression codecs
- Minimizes data fetching using HTTP range requests
- Includes TypeScript definitions
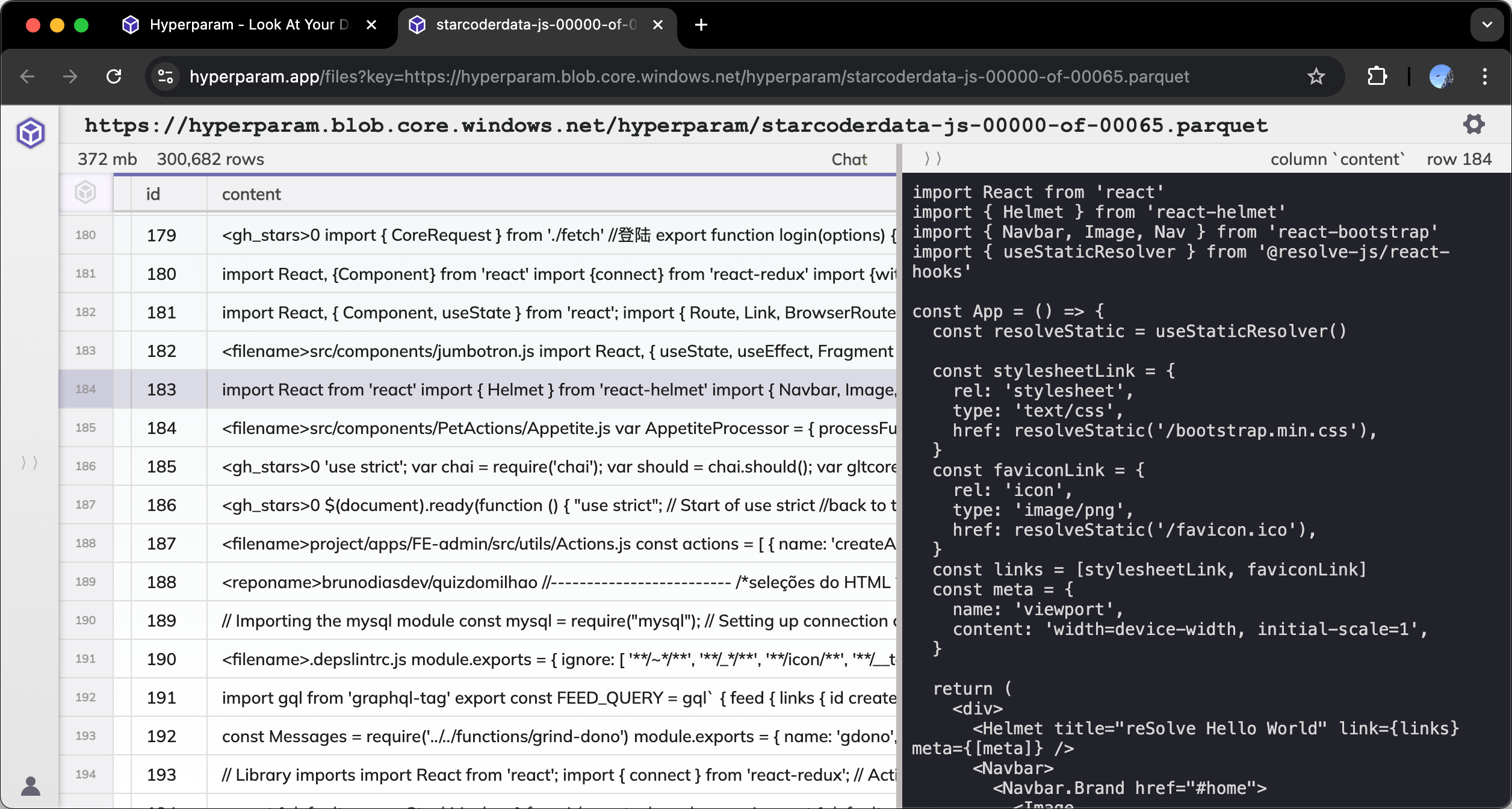
Parquet Viewer
Try hyparquet online: Drag and drop your parquet file onto hyperparam.app to view it directly in your browser. This service is powered by hyparquet's in-browser capabilities.
Quick Start
Browser Example
In the browser use asyncBufferFromUrl to wrap a url for reading asynchronously over the network.
It is recommended that you filter by row and column to limit fetch size:
const { asyncBufferFromUrl, parquetReadObjects } = await import('https://cdn.jsdelivr.net/npm/hyparquet/src/hyparquet.min.js')
const url = 'https://hyperparam-public.s3.amazonaws.com/bunnies.parquet'
const file = await asyncBufferFromUrl({ url }) // wrap url for async fetching
const data = await parquetReadObjects({
file,
columns: ['Breed Name', 'Lifespan'],
rowStart: 10,
rowEnd: 20,
})
Node.js Example
To read the contents of a local parquet file in a node.js environment use asyncBufferFromFile:
const { asyncBufferFromFile, parquetReadObjects } = await import('hyparquet')
const file = await asyncBufferFromFile('example.parquet')
const data = await parquetReadObjects({ file })
Note: hyparquet is published as an ES module, so dynamic import() may be required for old versions of node.
Parquet Writing
To create parquet files from javascript, check out the hyparquet-writer package.
Advanced Usage
Reading Metadata
You can read just the metadata, including schema and data statistics using the parquetMetadataAsync function. This is useful for getting the schema, number of rows, and column names without reading the entire file.
import { parquetMetadataAsync, parquetSchema } from 'hyparquet'
const file = await asyncBufferFromUrl({ url })
const metadata = await parquetMetadataAsync(file)
// Get total number of rows (convert bigint to number)
const numRows = Number(metadata.num_rows)
// Get nested table schema
const schema = parquetSchema(metadata)
// Get top-level column header names
const columnNames = schema.children.map(e => e.element.name)
AsyncBuffer
Hyparquet requires an argument file of type AsyncBuffer. An AsyncBuffer is similar to a js ArrayBuffer but the slice method can return async Promise<ArrayBuffer>. This makes it a useful way to represent a remote file.
type Awaitable<T> = T | Promise<T>
interface AsyncBuffer {
byteLength: number
slice(start: number, end?: number): Awaitable<ArrayBuffer>
}
In most cases, you should probably use asyncBufferFromUrl or asyncBufferFromFile to create an AsyncBuffer for hyparquet.
asyncBufferFromUrl
If you want to read a parquet file remotely over http, use asyncBufferFromUrl to wrap an http url as an AsyncBuffer using http range requests.
- Pass
requestInitoption to provide additional fetch headers for authentication (optional) - Pass
byteLengthif you know the file size to save a round trip HEAD request (optional)
const url = 'https://s3.hyperparam.app/wiki_en.parquet'
const requestInit = { headers: { Authorization: 'Bearer my_token' } } // auth header
const byteLength = 415958713 // optional
const file: AsyncBuffer = await asyncBufferFromUrl({ url, requestInit, byteLength })
const data = await parquetReadObjects({ file })
asyncBufferFromFile
If you are in a node.js environment, use asyncBufferFromFile to wrap a local file as an AsyncBuffer:
import { asyncBufferFromFile, parquetReadObjects } from 'hyparquet'
const file: AsyncBuffer = await asyncBufferFromFile('example.parquet')
const data = await parquetReadObjects({ file })
ArrayBuffer
You can provide an ArrayBuffer anywhere that an AsyncBuffer is expected. This is useful if you already have the entire parquet file in memory.
parquetRead vs parquetReadObjects
parquetReadObjects
parquetReadObjects is a convenience wrapper around parquetRead that returns the complete rows as Promise<Record<string, any>[]>. This is the simplest way to read parquet files.
parquetReadObjects({ file }): Promise<Record<string, any>[]>
parquetRead
parquetRead is the "base" function for reading parquet files.
It returns a Promise<void> that resolves when the file has been read or rejected if an error occurs.
Data is returned via onComplete or onChunk or onPage callbacks passed as arguments.
The reason for this design is that parquet is a column-oriented format, and returning data in row-oriented format requires transposing the column data. This is an expensive operation in javascript. If you don't pass in an onComplete argument to parquetRead, hyparquet will skip this transpose step and save memory.
Chunk Streaming
The onChunk callback returns column-oriented data as it is ready. onChunk will always return top-level columns, including structs, assembled as a single column. This may require waiting for multiple sub-columns to all load before assembly can occur.
The onPage callback returns column-oriented page data as it is ready. onPage will NOT assemble struct columns and will always return individual sub-column data. Note that onPage will assemble nested lists.
In some cases, onPage can return data sooner than onChunk.
interface ColumnData {
columnName: string
columnData: ArrayLike<any>
rowStart: number
rowEnd: number
}
await parquetRead({
file,
onChunk(chunk: ColumnData) {
console.log('chunk', chunk)
},
onPage(chunk: ColumnData) {
console.log('page', chunk)
},
})
Returned row format
By default, the onComplete function returns an array of values for each row: [value]. If you would prefer each row to be an object: { columnName: value }, set the option rowFormat to 'object'.
import { parquetRead } from 'hyparquet'
await parquetRead({
file,
rowFormat: 'object',
onComplete: data => console.log(data),
})
The parquetReadObjects function defaults to rowFormat: 'object'.
Binary columns
Hyparquet defaults to decoding binary columns as utf8 text strings. A parquet BYTE_ARRAY column may contain arbitrary binary data or utf8 encoded text data. In theory, a column should be annotated as LogicalType STRING if it contains utf8 text. But in practice, many parquet files omit this annotation. Hyparquet's default decoding behavior can be disabled by setting the utf8 option to false. The utf8 option only affects BYTE_ARRAY columns without an annotation.
If Hyparquet detects a GeoParquet file, any geospatial column will be marked with the GEOMETRY or GEOGRAPHY logical type and decoded to GeoJSON geometries. Set the geoparquet option to false to disable this behavior.
Compression
By default, hyparquet supports uncompressed and snappy-compressed parquet files. To support the full range of parquet compression codecs (gzip, brotli, zstd, etc), use the hyparquet-compressors package.
import { parquetReadObjects } from 'hyparquet'
import { compressors } from 'hyparquet-compressors'
const data = await parquetReadObjects({ file, compressors })
| Codec | hyparquet | with hyparquet-compressors |
|---|---|---|
| Uncompressed | ✅ | ✅ |
| Snappy | ✅ | ✅ |
| GZip | ❌ | ✅ |
| LZO | ❌ | ✅ |
| Brotli | ❌ | ✅ |
| LZ4 | ❌ | ✅ |
| ZSTD | ❌ | ✅ |
| LZ4_RAW | ❌ | ✅ |
References
- https://github.com/apache/parquet-format
- https://github.com/apache/parquet-testing
- https://github.com/apache/thrift
- https://github.com/apache/arrow
- https://github.com/dask/fastparquet
- https://github.com/duckdb/duckdb
- https://github.com/google/snappy
- https://github.com/hyparam/hightable
- https://github.com/hyparam/hysnappy
- https://github.com/hyparam/hyparquet-compressors
- https://github.com/ironSource/parquetjs
- https://github.com/zhipeng-jia/snappyjs
Sample project that shows how to build a parquet viewer using hyparquet, react, and HighTable:
- Hyparquet Demo: https://hyparam.github.io/demos/hyparquet/
- Hyparquet Demo Source Code: https://github.com/hyparam/demos/tree/master/hyparquet
Contributions
Contributions are welcome! If you have suggestions, bug reports, or feature requests, please open an issue or submit a pull request.
Hyparquet development is supported by an open-source grant from Hugging Face 🤗